Cuando uno entra en esta dirección
http://books.google.es/books?id=vaDm3OE2gOkC&printsec=frontcover&dq=embriologia#PPP13,M1
Y para ver las imágenes (captura de imágenes de texto) Uno quiere guardarlo de la
forma tradicional y no puede.
Para guardarlo se hace lo siguiente con firefox:
Herramientas/Información de la página/pestaña MEDIOS
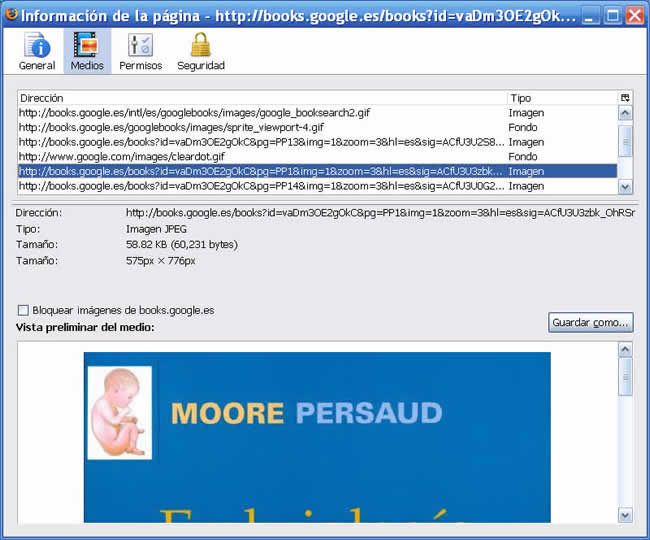
Ahora estando en esta ventana uno puede guardar la imagen que quiera
Al ver la imagen
http://books.google.es/books?id=vaDm3OE2gOkC&pg=PP1&img=1&zoom=3&hl=es&sig=ACfU3U3zbk_OhRSrkWCjGFyeGSoVepft_A&w=575
Al lado derecho está en tipo = IMAGEN
Cuando uno le da click al botón Guardar Como
Sale la típica ventana. Pero en el tipo de archivo no especifica una extensión de imagen (jpg, png o etc.)
Cuando uno ya lo guardo y quiere abrir, se encuentra con un archivo html
Yo pude ver el contenido de ese archivo. En realidad ese html es una extensión de imagen (jpg o etc.)
Ahora la gran pregunta es como esta implementado todo esto... (De que forma google protege sus imágenes)
Sugerencias ideas. Son todas bienvenidas...
Por mi parte actualmente me encuentro trabajando en este Proyecto
Que por cierto muy pronto estará listo... y no tengo mucho tiempo para ver este detalle
Haber si alguien con más tiempo nos da la respuesta. De esta protección de imágenes
Saludos y que todos tengan un buen día.
PD: Se preguntaran de que sirve esto si con la tecla control + imp pant se puede capturar
El caso es que para eso tengo una supuesta solución (al pulsar control o alt se activa en la imagen una marca de agua, solo aparece cuando uno presiona esas teclas)



